Minimum Viable Data Scientist
What is this doc?
After a few years as a machine learning engineer, I often found myself helping other data scientists tackling development issues. How to write proper code, how to package code to production, how to scale... These are simple things that common data science teaching programs don't explain at all.
This bag of tips and tricks is aimed at beginners, fresh grads and those who want to improve their data science practice. It should give enough to reach a comfortable level of quality in data science. The goal is to be a minimum viable data scientist.
This is an opinionated writing. Some parts are better explained elsewhere, such as code style or how to use git. It is also strong minded. Don't hope to find R stuff or notebooks.
From experiment to craftmanship
What is data science
Data science can be defined as the analytical process that extract value and create products from data. It can take many shapes depending on the business and the IT culture of the company.
So what is data and what do we want to do with it? Fundamentally, data is a raw material - you can't get value from it without any form of processing. That's why it needs to be refined. An image that is commonly used in Knowledge management is the DIKW pyramid: Data gives Information, which gives Knowledge and then Wisdom. Now there are multiple critics about this theory (for example, here). But it gives a nice sense of what needs to be done to operate data. Having terabytes in a data lake is an asset that might not hold any value if not processed. And data science is that process.

For example, a list of customer in itself doesn't yield any information. However, summary statistics could give customer segmentations, which in turn can help take good business decision, like adapting products to the market. Here is the keyword : decision. Data science doesn't hold value in itself, it's value is defined by the business decisions it allows to take.
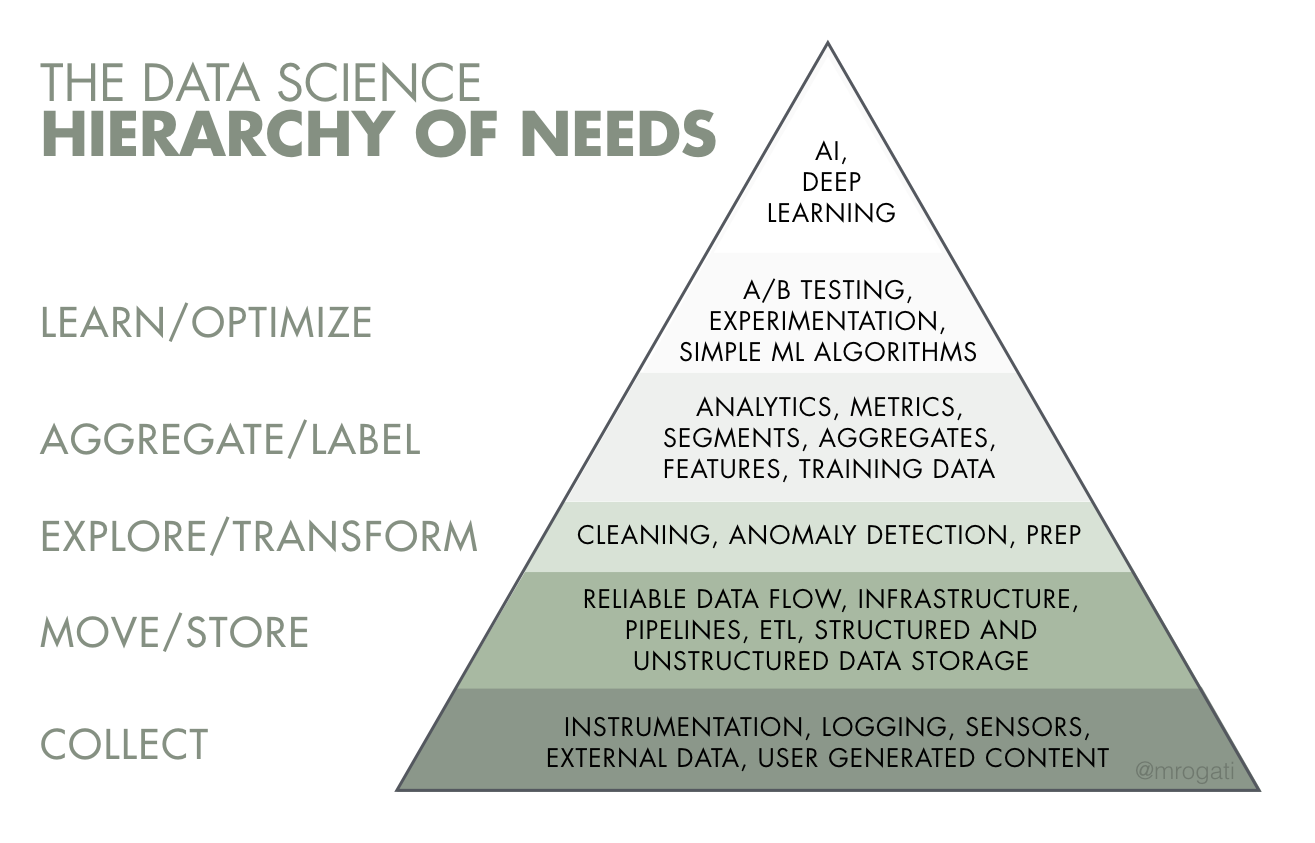
Another good inspiration is the data science pyramid of need. It explains all the step an organization need to take before being able to draw the power of deep learning. And data science encompass all of these steps. If you think data science is only machine learning, then you are sorely mistaken. As outlined in many articles, data management will take up to 80% of your time.
There are multiple data based fields: quants in finance, business intelligence, data mining and so on. What distinguish data science then ? Nothing much since data science is an umbrella term that encompass all data-driven fields. What really gave a speed boost to data science is twofold. First, datalakes are now a commodity. Any business can store terabytes of data with little cost. Second, the computing power has exploded beyond sectors that could afford HPC. It has never been easier to find large computational ressources to process data - think Apache Spark, GPU and so on. The consequence is the fast evolution of machine learning algorithms. New deep learning and NLP models have the highlights, but in fact it has never been so easy to train a simple model.
Data scientist and friends
Data science roles are multiple. Here is a brief outline of profiles often found in data teams.
Data analyst are people with substantive business acumen and some quant knowledge. They craft insight with tools like SQL or excel. They often help data scientist understand the data and do feature engineering.
Data scientist bring the core business value to the team. Coming mostly from research and quantitative fields, they somewhat lacks development skills at the moment...
Data engineers are the master of data logistics. They build pipelines for data, databases and datalakes. They are IT pros. Not the hero we though when building a data team, but the hero we need.
Machine learning engineers are a cross breed between the IT skills of a data engineer and ML craftiness of a data scientist. They build models for and in production. Find one or two for your team, but beware, there is no training for this role except experience.
The awful truth
This is not a secret: most data scientist don't have any kind of formal software engineering training. A classic machine learning tutorial show only scripts or jupyter notebooks. Software Engineering outlined and solved many issues that plagues data science today, from the 1968's Software crisis to the Agile manifesto.
In order to do proper data science, a data scientist need to ask himself this question :
If anyone or myself read this code in one or two year, can they:
- run the code
- put the code / the model into production
- understand what I did
- obtain the same result with the same data
- improve the code without much overhead
A data scientist should be able to do reproducible and consistent research. This ultimately leads to production-ready projects. Reproducible means you should be able to run it on a new computer - or a container, as we will see later. Consistent means simply that the code should adopt a style and stick to it.
When asked what is a data scientist, Josh Wills, Senior Director of data Science at Cloudera, answered (in The Data Analytics Handbook Pt1):
“Someone better at statistics than any software engineer, and someone better at software engineering than any statistician.” The vast majority of statisticians can write code, or rather they think they can write code in SAS, or R, or Python. However, it is usually really bad code that is only intended to be used by the person who wrote it. I think that what makes you a good software engineer is the ability to write code for other people. To be good at coding you must understand how other people are going to use it. Statisticians don’t always have that inherent skill."
This is the challenge this repo is up to.
Learn the basics before going further
There are great book about machine learning and statistics that you can read with the content of this repo. Berkeley Handbook and Google ML crash course should give you the knowledge about data science you need. There are many other sources, but these two are well-built.
A quick look at a trainee data science project would usually show some of the following mistakes:
-
Consistency common mistakes
-
not following code style guides (such as PEP8 for python)
- files with versionned names (file_v1.py, file_v2.py...)
-
variable names not clear such as x or my_var
-
Reproducibility common mistakes:
-
absolute path (C:\users\my_name\my_data... such a common occurrence !)
- no way to reuse / recreate the data used in the analysis
-
no pipeline, DAGS or script to run the analysis
-
Development mistakes:
-
parameters can't be changed at run time
- no refactoring - the same code in two places
-
functions are not documented
-
Git mistakes:
-
not using git!
- saving data in git
- wrong commit messages format
Some of these mistakes are easily fixed - PEP8 can be enforced with flake8 or alternative linter. However, doing good pipelines requires a bit more work.
Before delving into code and project management for data science, here are some necessary resources on python development that are mandatory reading before going further. Check it, read it often. They are basics.
| ID | TL;FR | Link |
|---|---|---|
| PEP8 | Standard python style guide | link |
| Google python style guide | link | |
| PEP257 | Python documentation | link |
| Hitchhiker's guide to python documentation | link | |
| flake8 | A tool to lint code errors | link |
| git | Writing great commit messages | link |
| git | Interactive tutorial on git | link |